
KUBERNETES CONCEPTS AND ARCHITECTURE

Kubernetes was developed as a management tool for the orchestration of microservices across a distribution of cluster nodes. It provides a highly reliable infrastructure with brilliant features. K8s enables zero-downtime deployment, automatic rollback, scaling, and self-healing of containers. Self-healing procedures include auto-placement, auto-restarts, auto replication, and scaling of containers based on CPU usage. Kubernetes is very portable, capable of running across cloud services like AWS and Azure. On top of that, it also runs on physical machines.
In this article, you will discover the basics of how Kubernetes operates. But first let’s dig deeper into what Kubernetes is. Kubernetes’ definition describes it as a system for container management. Though it’s not the only one available on the market, its effectiveness makes it the most popular. Originally it was developed by Google as a branch of their Borg project.
Kubernetes is a powerful tool that manages the clusters of containerized applications. This process in computing is referred to as orchestration. It coordinates the different microservices that result in a complete application when combined. Furthermore, it automatically and continuously monitors the condition of the clusters and makes adjustments to suit the required conditions. Kubernetes combines the virtual and a physical machine into a unified API surface. This allows for easy deployment, scaling, and management of containerized applications. Kubernetes workflow always compares the current state of operations with the desired results and moves the processes toward them. Once you have an understanding of the Kubernetes overview from this article, be sure to check out the Kubernetes use cases and advantages by OpsWorks Co.
KUBERNETES ARCHITECTURE
The following Kubernetes review of its architecture will answer the question, how does Kubernetes work? As the orchestrator of different containers, it was designed in a highly modular manner. Each piece of technology has a necessary group services that depend on it. With the containment of a module inside a larger one that depends on it to function, Kubernetes architecture provides the means for this to occur seamlessly. To achieve this, Kubernetes features a decentralized architecture concept that functions on a declarative model and uses the architecture concept of the desired state.
The process of the desired state occurs in the following manner. Firstly, the desired state of an application is created into a manifest by the administrator. Using kubectl, the file is transferred to the Kubernetes API server. Kubectl is the Kubernetes default command line that interacts with the API server and sends commands to the master node. From the API, the file is transferred to the Key-Value Store (etcd), which is a database used to store the application’s desired state. Kubernetes uses the information on the file to implement the new desired state by making relevant changes to the current state of the applications within the cluster to achieve the newly required state. Finally, the Kubernetes objects monitor the current state of the clusters to ensure that they do not deviate from the desired state. The monitoring process is continuous and automatic, ensuring that the desired state of operation is always maintained.

Master Node in Kubernetes Architecture
The Master node receives input from the administrator through the Command-Line Interface (CLI) or User Interface (UI) via an API. These commands contain the required states of the pods, replication instructions, and services to be maintained by the Kubernetes master node.
API Server – the only Kubernetes component that the administrator directly interacts with. The API server is the central management system that receives all requests for modifications. API communicates directly with the key-value store ensuring that the data contained in the key-value store corresponds with the operation of the deployed pods. It also is the communication center for the internal master components and external user components.
Key-Value Store – also called etcd. Its function is to store and back up cluster data. The stored data includes the configuration and state of the cluster, such as the number of pods and namespace. The Kubernetes multi-master node retrieves parameters from the etcd concerning the state of the nodes, pods, and containers. For security reasons, it is only accessible through the API server. The key-value store facilitates notifications about configuration changes to the clusters through the assistance of watchers. Notifications are API requests on the cluster node to trigger the update of information in the node’s storage.
Controller – an operational function of the controller is to continuously check the state of the pods against the desired state. If there are differences between the two, it performs operations to change the current state to suit the desired one. It also runs background controller processes to regulate the state of the cluster and perform routine checks. Controller processes that are run include a replication controller, which controls the number of pods in a cluster. If the administrator inputs new parameters, the Kubernetes controller spots the change in the service configuration, and it starts to perform processes to achieve the newly required state.
Scheduler – responsible for assigning new requests from the API server to appropriate nodes. Depending on the service’s operational requirements, the pods are deployed on the best-suited node. However, if there is no pod with the required parameters the pod is placed in pending mode until such a node becomes available. The scheduler runs each time there is a need for scheduling. The scheduler knows the state of all the resources, and, therefore, allocation becomes even easier.
Worker Node in Kubernetes Architecture
The worker nodes listen to the API server for new service configurations. If there are any, they execute and report the results to the Master node. It contains 3 Kubernetes components which include:
Kubelet runs on every node. It is the main service on a node. It watches for new or modified tasks from the API server, executes, and then gives feedback to the Master Node. It monitors and ensures that the pods are running in the desired state. If, however, there is a faulty pod, it reports to the Kubernetes Master, which then gives new corrective measures based on the received information.
Container runtime pulls images from a container image registry and starts and stops containers. This function is usually performed by third-party software, such as Docker.
Kube-proxy runs on every worker node, dealing with host subnetting of the node. Moreover, it implements local IPtables and ensures that each node receives its IP address. It also performs routing and traffic load balancing across various isolated networks in a cluster.
KUBERNETES CORE FEATURES
Container runtime
Kubernetes uses Container Runtime Interface (CRI) to manage master containers without having to deal with the runtime used. Kubernetes uses a container management system called Containerd, and it is the default container runtime.
Network plugin
Among other responsibilities, the container orchestration system manages the communication network between containers and services. Kubernetes uses Container Network Interface (CNI) as an interface between the cluster and various network providers. However, Kubernetes is not limited to CNI as there are other network providers like Contiv and Flannel. The reason for numerous network providers is to allow for diversity. As a program that was designed to run on multiple platforms, this allows for an increased variety of communication options between Kubernetes containers. This is only possible with numerous network providers to choose from.
Volume plugin
A volume is a storage available for the pod. A pod is composed of either one or more containers that are managed as a single unit by Kubernetes.
Image registry
Kubernetes must contact an image registry (whether public or private) to be able to pull images and spin out containers.
Cloud provider
As a flexible program, Kubernetes is deployable on any platform. Usually to save costs, many prefer to use cloud providers like AWS and Azure. The cloud provider enables Kubernetes to perform scalability. Furthermore, it facilitates resource provision actions such as load balancing, access to cloud storage, and utilization of the inter-node network.
Identity provider
In a small company, each user can have their accounts created for each one. But in a large enterprise with hundreds or thousands of users, this can be an issue. Creating individual accounts for each user in an enterprise is a tedious task. However, Kubernetes designers had that in mind and came up with another authentication system. This system enables you to use your identity provider system to authenticate users as long as it uses OpenID connect.
CONTAINERS AND MICROSERVICES
In the past software deployment was done physically. This was not only difficult to perform but also time-consuming and error-prone. There was also the issue of buying physical machines, which had more storage and processing power than what was required. This further increased the costs incurred by the company, including requisite routine maintenance checks. Later on, virtualization was created. It allowed different software to be installed on the same physical machine. This reduced costs incurred by the company as they only needed to buy one physical machine. The use of one physical machine to host multiple virtual ones revolutionized the deployment process. However, virtualization required the installation of the operating system of every application.
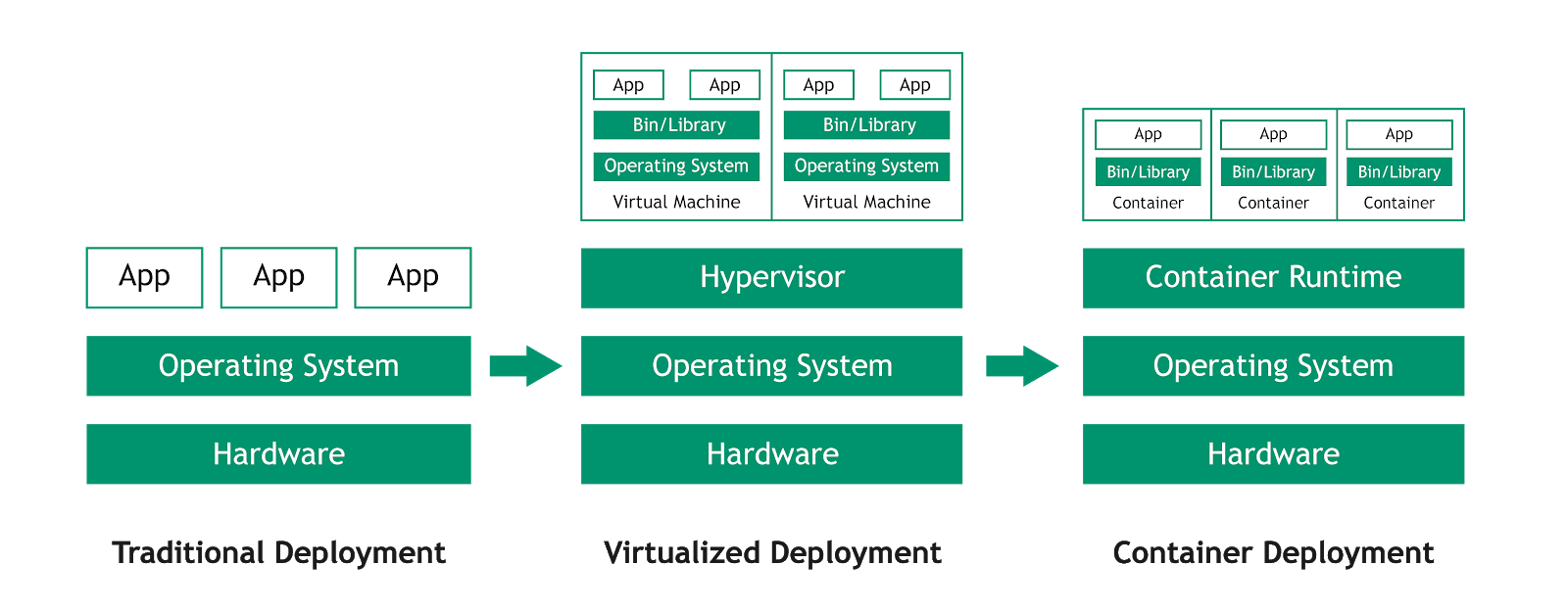
Then, the container concept was introduced, which allowed even smaller units than the virtual servers to be created. Unlike virtual machines, which offer hardware isolation, containers provide process isolation.
A container is a set of processes on the operating system that operates in complete isolation from other processes. It operates through Linux kernel features like Cgroups and Chroot. The utmost advantage of Kubernetes containers is that you only need one physical host and one operating system. In this setup, you can run as many applications as your hardware can manage. This saves storage, memory, and CPU power as the number of OS needed to run applications is reduced.
WHAT IS CONTAINER DEPLOYMENT
Container deployment is a more flexible and efficient deployment model. It enables multiple applications to share the same underlying operating system. It provides the efficiency of containers which are portable across clouds and almost all operating system distributions. The container architecture allows for the separation of applications into smaller independent units, which are easier to run. The best thing about these units is that they can be deployed on multiple machines and dynamically managed. The segmentation provided by K will be too complex to be managed manually. K is the solution to effectively automate the management of moving parts involved in the application process.
KUBERNETES CONCEPTS
Pod
What is a Kubernetes pod? It is a container or containers that are controlled as a single application. A pod contains storage resources, application containers, and a unique network ID. Furthermore, it includes service instructions on how the containers should operate.
Service
With pods being volatile, their immediate state at a particular moment is not guaranteed. Therefore, a service acts as a gateway for client pods to send requests without the need to keep track of the actual pods that make the service. A service is a representation of a logical set of pods.
Volume
Volume applies to a whole pod. Kubernetes concepts ensure that the data is preserved across container restarts. The volume is only removed when the pod is destroyed. A pod can have multiple volumes associated, and they can be of different types too.
Namespace
Resources inside a namespace are unique and, therefore, cannot access other resources in a different namespace. Furthermore, allocation of resources to a particular namespace can be done to prevent it from consuming more than its share.
Deployment
It contains configurations for the desired state of a pod in a manifest file. The deployment controller then implements the new configurations to the current state until it matches the desired state. The updates can be creating, deleting, or duplicating the existing pod.
PODS
A pod is the basic element of scheduling in Kubernetes. It facilitates the container being part of the cluster. This allows for the scaling of apps, as this can only be done by adding and removing pods. To launch a container the Master node schedules the pod on a specific node and coordinates with the container runtime.
Kubernetes pods are volatile. Therefore, if a pod unexpectedly malfunctions, Kubernetes creates and runs a new replica in its place. The replica is identical to the malfunctioning one, except for DNS and IP address. The flexibility of Kubernetes allows a new pod to be created in a different location to seamlessly replace the malfunctioning one.
One of the best features of Kubernetes is that it monitors the health of pods, and malfunctioning ones are automatically replaced by new ones. This ensures that the application has zero downtime. Pods are linked with services through key-value pairs called labels and selectors. A service automatically searches for a new pod with a label that matches the selector. This process efficiently removes faulty pods and replaces them with new ones. Finally, Kubernetes monitors the states of the pod architecture and adds or removes them to match the required state.
SERVICES IN KUBERNETES
Monitoring services is an important task in maintaining a healthy Kubernetes environment. It does this through integrated DNS service, for example, Kube-DNS or CoreDNS, depending on the cluster version. These DNS services create, update and delete DNS records for services. They also perform the same function for associated pods. This enables applications to target other services or pods in a Kubernetes cluster through a simple and efficient naming scheme.
There are four different types of services, and they have different operations. First, there is ClusterIP, which is the default type. It exposes the service on an internal IP, making the service only reachable within the Kubernetes cluster. Followed by NordPort, it provides numerous options for developers to customize their load balancers, altering how Kubernetes works. It does this by exposing the service on the Nord IP at a specific port. This further permits the developers to implement their configurations on platforms not fully supported by Kubernetes.
Next is the LoadBalancer, which uses the cloud provider’s load balancer to perform external services. This option is preferable, especially when the cloud balancer is supported by Kubernetes. Finally, there is ExternalName. It is often used to create a service within the Kubernetes setup to represent an external datastore. For example, the datastore can be a database that runs externally to Kubernetes.
BENEFITS OF KUBERNETES
Below is the Kubernetes overview, which explains how it can improve the operations of a company.
Scalability – it allows set configurations to be maintained. For example, if the threshold for CPU utilization is 80%, and the application is using 150%, Kubernetes will start a new pod to average the CPU utilization to the set limit. It also provides load balancing across numerous applications.
High availability – it accomplishes this through the creation of replica pods. The replica pods will act as a standby for functioning ones, ready to immediately take over when one in operation starts to fail. This type of setup ensures high availability as the application cannot crash. It eliminates downtime and its associated costs.
Security – Kubernetes has security features on multiple levels, which include cluster, application, and network levels. The API endpoints are secured through transport layer security. This ensures that only authenticated users can access and execute operations on the cluster.
Portability – it can be installed on different platforms, which include physical machines, virtual machines, and cloud services.
Ready to implement Kubernetes and make use of its advantages for your business? Then you need an expert DevOps team. OpsWorks Co. has a team of professionals with extensive knowledge and impeccable skills in the field. They have already boosted a number of businesses whose owners have already enjoyed simplified management and increased profit. Now it is your turn to try.